# JVM Warm up ?
JVM 서버는 배포 직후 Latency가 존재한다.
그 이유는 java는 기본적으로 `compile -> byte code -> interprete` 과정을 거치는 언어이며, compile시 바로 번역되는 전통적인 컴파일 언어보다 초기 실행 속도가 느리기 때문이다.
그래서 java는 이를 JIT 컴파일러를 통해서 극복한다.
JVM이 실행될수록 JIT 컴파일러는 최적화를 통해, 자주 호출되는 메소드들을 네이티브 코드로 컴파일하고 캐시에 저장해두어 점차 성능을 향상시킨다.
따라서, API가 최초로 구동되고나면 상대적으로 높은 최적화로 컴파일된 메소드들이 많지 않기 때문에, 처음 요청은 느릴 수 밖에 없는 것이다.
물론 클래스 로딩 외에도 다양한 이유가 있을 수 있다.
(DB 커넥션 latency, 리플렉션 처리, lazy와 같은 클래스 지연 로딩, thread pool 초기화 등)
하지만, 그 중에서도 JIT 컴파일러 동작 방식이 애플리케이션 초기 Latency의 가장 주요한 원인 중 하나다.
그렇다면 JIT 컴파일러는 정확히 어떻게 동작하는걸까?
# JIT 컴파일러 동작 방식
JIT 컴파일러의 동작 방식을 이해해야, 그에 맞는 적절한 웜업 방식을 적용할 수 있다고 생각했다.
앞서 언급한 것처럼, java는 코드를 실행할 때 모든 메소드를 바로 컴파일하지 않는다.
"코드가 한번만 실행된다면 컴파일은 헛수고다. 컴파일해서 컴파일된 코드를 한번만 실행하는 것보다 자바 바이트코드를 인터프리트하는 편이 더 빠르다.
JVM이 특정 메소드나 루프를 실행하는 시간이 길어질수록, 코드에 대해 얻어지는 정보가 많아진다. 이를 통해 JVM이 코드를 컴파일할 때 최적화를 적용할 수 있다."
- (출처: 자바 성능 튜닝)
즉, 코드가 실행될수록, JVM은 다양한 실행 프로파일 정보를 수집하고, 이를 기반으로 JIT가 점진적으로 최적화를 적용해간다.
그렇다면 이 최적화는 어떤 방식으로 진행될까?
JIT 컴파일러는 기본적으로 Tiered Compliation이라는 매커니즘을 사용한다.
즉, 자주 실행되는 코드일수록 더 높은 Tier에서 더욱 정교한 최적화가 이루어진다.
이때 컴파일 단위는 주로 메소드 단위이며, 네이티브 코드로 변환된다.
Tier 구조는 다음과 같다.
| Tier | 설명 | 컴파일러 |
| Tier 0 | 인터프리터 | 없음 |
| Tier 1~3 | C1 컴파일러 (경량 최적화 + 프로파일링) | C1 |
| Tier 4 | 고급 최적화 (최종 네이티브 코드) | C2 |
이를 그림으로 보면 다음과 같다.

TieredCompilation 활성화 여부 확인
Java 8 이상에서는 기본적으로 활성화되어 있을 것이다.
java -XX:+UnlockDiagnosticVMOptions -XX:+PrintFlagsFinal -version | grep Compilation
Threshold 확인
$ java -XX:+UnlockDiagnosticVMOptions -XX:+PrintFlagsFinal -version | grep Threshold
intx Tier2BackEdgeThreshold = 0 {product} {default}
intx Tier2CompileThreshold = 0 {product} {default}
intx Tier3BackEdgeThreshold = 60000 {product} {default}
intx Tier3CompileThreshold = 2000 {product} {default}
intx Tier3InvocationThreshold = 200 {product} {default}
intx Tier3MinInvocationThreshold = 100 {product} {default}
intx Tier4BackEdgeThreshold = 40000 {product} {default}
intx Tier4CompileThreshold = 15000 {product} {default}
intx Tier4InvocationThreshold = 5000 {product} {default}
intx Tier4MinInvocationThreshold = 600 {product} {default}
Threshold는 "호출 횟수" 또는 "루프 백엣지(backedge)" 기준으로 설정되어 있으며, 이 값을 초과하면 해당 Tier로 컴파일이 시도될 수 있음을 의미한다.
Threshold는 조절이 가능하며, 보통 Threshold를 조절하는 이유는 다음과 같다.
- 애플리케이션 워밍업하는데 필요한 시간을 약간 절약한다.
- 컴파일 임계치를 낮추지 않으면, 절대로 컴파일되지 않는 메소드가 존재한다.
코드 캐시 사용량 확인
$ jcmd [PID] Compiler.codecache코드 캐시 값 또한 조정할 수 있으며, 대부분의 Java 앱에서는 기본값으로 충분하다.
따라서, 코드 캐시는 제약이 없다고 간주해도 되며, JIT가 컴파일 해야한다고 생각되는 코드를 계속 컴파일 한다는 의미이다.
출처: https://docs.oracle.com/javase/8/embedded/develop-apps-platforms/codecache.htm#BABBACEJ
만약, 이 코드 사이즈가 가득차게되면, JIT는 이미 컴파일된 메소드를 플러싱한다.
$ java -XX:+PrintFlagsFinal -version | grep UseCodeCacheFlushing
Flushing은 기본적으로 LRU(Least Recently Used) 방식으로로 제거하며, 이는 최근 실행되지 않았거나 자주 호출되지 않는 네이티브 코드를 캐시에서 삭제한다는 것을 의미한다.
Flushing 방식은 Java 8 이상에서 더욱 정교하게 동작하며, G1GC 같은 GC와도 잘 통합이 되어있다.
이보다 더 자세한 LRU 규칙을 알기에는 JIT가 매우 복잡하고 정교하게 설계되어있기 때문에, 위처럼 일반적인 설명만 제공하는 것이 대부분이다.
모든 메소드를 C2로 컴파일하면 안되나?
그렇다면 나는 여기서 의문이 생겼다.
캐시 사이즈를 충분히 확보해두고, Threshold값을 낮춰놓으면, 모든 코드가 Tier4로 가서 가장 빠르게 동작할 수 있는거 아닐까?
이 의문에서 내가 알아낸 내용은 다음과 같다.
- JIT 컴파일 비용
- 모든 메소드를 네이티브 코드로 컴파일 하는 것은 비효율적이다. 때론, 인터프리팅이 더 나은 경우도 존재한다.
- 메모리 관리
- CodeCache는 단순한 배열이 아니다.
- 메소드 inline 변화나 Fragmentation 처리 등 복잡한 관리가 필요
- CPU 캐시 효율
- 너무 많은 코드가 올라가있으면, CPU L1/L2 캐시 효율이 떨어져 오히려 성능이 저하될 수 있다.
- Threshold는 충분조건이지 필수 조건이 아니다.
- Threshold를 넘었다고해서, 반드시 컴파일되는 것은 아니다.
- 그도 그럴 것이, 서버가 오래떠있으면 모든 메소드의 Threshold가 넘길 것이 자명하기 때문
- 해당 메소드가 자주 호출되는가? 최적화 가치가 충분한가? 실행경로가 다양한가?
- 등을 추가로 확인한다.
즉, JIT 리소스가 충분해도 이득이 없다고 판단되면, C2 컴파일을 생략한다.
모든 메소드를 무조건 C2로 컴파일하는 것이 최선은 아니다.
# Warmup을 적용하는 방법
JIT 최적화의 원리를 이해했으니, 이에 맞는 효율적인 웜업 전략은 다음과 같이 구성할 수 있다.
- 자주 호출되거나 지연이 생길 가능성이 있는 API를 스크립트로 선호출
- 실제 트래픽 기록을 바탕으로 사전 호출 시나리오 구성
- 소량의 실제 트래픽을 선반입하여 자연스러운 프로파일 수집 유도
참고: AOT등의 정적 컴파일 방식은 이글의 범위에서 제외
# 사전 정의 API 호출 스크립트 적용
우리는 비교적 자주 호출되고, 무거운 API 위주로 API 요청 스크립트를 작성했고, 이를 웜업에 활용했다.
이러한 스크립트를 통해, Tier 별로 어떻게 적재되는지 다음의 옵션을 JVM에 추가하고, 로그 파일을 분석했다.
-XX:+UnlockDiagnosticVMOptions -XX:+LogCompilation
웜업 요청의 호출 횟수를 늘릴수록, 더 높은 Tier의 컴파일 비율이 증가하는 것을 확인할 수 있었다.
따라서, 웜업 테스트 결과를 보면 웜업 + 카운팅 횟수 증가를 해야 조금 더 많은 컴파일을 할 수 있지만, 그만큼 배포 시간이 늦어진다는 트레이드 오프를 가지고 있다.
이제 이정도의 최적화로 배포 시 Latency가 발생하지 않는지 확인을 했지만, 결과적으로는 이 방법으로는 여전히 Latency가 발생했다.
또한, 스크립트를 통한 웜업 방식에는 다음과 같은 한계가 있었다.
- 사전으로 만들어 낼 수 있는 데이터와 API가 한정적이다. (보안과 권한 이슈 등)
- 과도한 사전 API 요청으로 웜업 시 서버가 위험할 수 있다. (특히 휴먼 에러 문제)
- 실제 트래픽 기반은 아니므로 JIT가 고도화된 최적화는 할 수 없다.
그럼에도 불구하고, 가장 단순하고 많이 사용되는 웜업 방식이며, 일반적인 서버 환경에서는 이 방법만으로도 충분할 수 있다.
그러나 우리의 경우, 대규모 모놀리스 서버 + 수십만 TPS 요청 이상을 처리하는 높은 트래픽이라는 특수성이 존재했기 때문에, 우리는 실제 API 요청 기록을 바탕으로 웜업을 진행하는 방식으로 방향을 돌렸다.
# 실제 API 요청 로그 기반 웜업
우리는 API 로그를 ELK 구조로 Elasticsearch에 저장하고 있었으므로, 이 데이터를 활용했다.
다만, 이는 실제 요청 데이터를 활용하는 것이므로, 신중한 필터링과 제약조건 설정이 필요했다.
1차적으로 다음과 조건의 데이터를 API 로그에서 추출했다.
- 최근 5분 이내
- 데이터 개수 N건
- GET 요청
- 특정 URL
- 응답시간이 N초 이내
- 응답 Status Code는 200
하지만 이 조건에는 다음과 같은 문제가 있었다.
- 특정 시간에 몰린 특정 API만 수집될 수 있다.
- 자주 호출되지만 웜업에 효과없는 API가 다수 포함될 수 있다.
정교화된 필터링 전략
위 문제를 해결하기 위해, 다음과 같이 조건을 조정했다.
- 시간 범위를 1시간으로 확장
- 랜덤 추출: 1시간 동안의 요청 중 N건을 랜덤 추출하여, 실제 트래픽 분포를 유사하게 반영
- 정확한 비율을 맞추기 위해, Elasticsearch에서 Aggregation을 사용할수도 있지만, 성능 부담과 실효성 문제로 랜덤 추출로 대체
- 자주 호출되지만, 비교적 가벼운 API는 제외
- Predefined 주요 API도 M건 추가
- 기존 방식에 도입했던 것으로 안정성을 위해 병행 적용
웜업 데이터 저장 방식
우리는 100개 이상의 Pod을 운용하고 있다.
따라서 배포 시 모든 Pod이 동시에 ES에 웜업 데이터를 요청하면, 성능 저하가 발생할 수 있음을 우려했다.
이를 방지하기 위해, 다음과 같이 구성하였다.
- 배포 시 실시간 요청이 아닌, 사전 배치 작업으로 데이터를 추출
- 공용 저장소에 저장하여 각 Pod이 이를 참조하도록 구성

웜업 데이터 적용
이제 웜업 데이터는 준비가 됐으니, 이 데이터를 어떻게 적용할지의 문제만 남았다.
k8s 환경에서 JVM 웜업을 적용할 수 있는 선택지는 다양했다.
- readinessProbe에 연동
- startupProbe에 연동
- entrypoint 스크립트에 연동
- ApplicationStartEvent에 연동
결론적으론 ApplicationStartEvent에 연동하는 방법을 선택했는데, 이유는 다음과 같다.
- readinessProbe 연동
- 장점: k8s의 기본 동작과 잘 통합됨
- 단점
- 웜업이 끝날 때까지 readinessProbe 실패 상태가 지속됨
- 그에 따라 periodSeconds를 조절해야할 수도 있음
- 실패 로그가 쌓이며 오탐을 유발할 수 있음
- startupProbe 연동
- 장점: 논리적으로 적절하며, k8s의 설계 목적에도 부합
- 단점: 우리가 사용하는 k8s 버전에서는 미지원
- entrypoint 스크립트 연동
- 장점: k8s에 의존적이지 않음
- 단점: IDE 추적 어려움, 유지보수 복잡성 증가
- Spring ApplicationStartEvent에 연동 (최종 선택)
- Spring 개발자에게 친숙한 방식
- JVM이 안정적으로 구동된 이후에 웜업 수행 가능
웜업 호출 로직 구현시 고려해야할 점
- 병렬 호출
- 순차 호출은 웜업 시간 지연 및 서버 커넥션 활용 저조
- 단, 서버가 무리되지 않는 수준의 병렬성 필요
- 보수적인 타임아웃과 루프 횟수 설정
- 외부 호출포함 API도 고려
- 웜업 호출 구분을 위한 Flag 추가
- HTTP 헤더 등에 별도 플래그를 심어 웜업 요청임을 명확히 구분
Live 트래픽 기반 웜업 병행 적용
여기까지 적용했을 때, 기존에 비해 드라마틱하게 초기 요청 Latency가 줄어들었다.
하지만, 여전히 낮은 비율로 Latency가 발생하는 요청이 존재했다.
따라서 조금 더 안전한 배포를 위해, 리얼 트래픽 기반의 웜업도 적용하였다.
기존에는 Blue/Green 배포 -> 즉시 스위칭하는 구조
- 배포 인스턴스에 3분간 소량의 트래픽을 유입
- 웜업 완료 후, 전체 스위칭
Live 트래픽 웜업만 적용하면 위험한 이유
리얼 트래픽 기반 웜업도 좋은 방식이지만, 단독으로만 사용할 경우 우려되는 점이 있다.
- 트래픽이 높은 서버에서는, 소량의 트래픽이라도 Cold 인스턴스가 처리하는 요청은 사용자 경험 저하로 이어질 수 있음
- 인스턴스 스케일아웃이 필요한 경우 Latency 이슈 발생 가능성 높음
# 적용 결과
정리하자면, 우리는 최종 웜업 방법까지 3단계를 거쳤다.
그 3단계의 적용 결과는 아래와 같았다.
1단계. Predefined api request based warmup (사전 정의 API 요청 기반 웜업)

2단계. Real Traffic log based warmup (실제 요청 로그 기반 웜업)
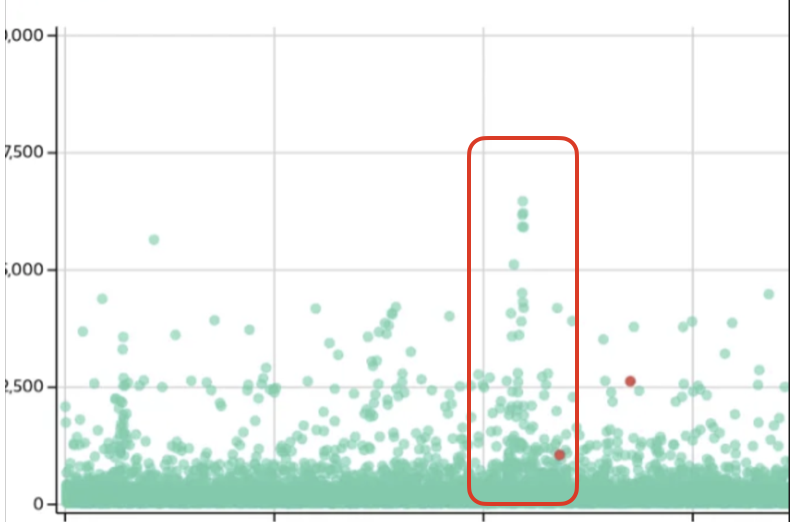
3단계. Real Traffic log based + Live Traffic based warmup

# 마무리
JVM 웜업 적용은 생각보다 단순하지는 않았다.
JIT 구조의 알맞은 이해와 시스템 규모에 맞는 전략적 접근이 필요했다.
우리는 총 3단계의 우여곡절을 겪고 최종적으론 안정적인 배포를 진행할 수 있었다.
'Programming > Java & JSP & Spring' 카테고리의 다른 글
| JVM 메모리 누수 트러블슈팅 (Native memory leak) (1) | 2024.11.16 |
|---|---|
| [Spring] Guava RateLimiter 사용법 (spring throttling) (0) | 2022.03.20 |
| [Spring] 외부 API 호출 서비스 테스트코드 작성하기 (WebClient & MockWebServer) (0) | 2022.03.13 |
| [Spring boot] Hikari CP 적용 & 커넥션 누수 이슈 (0) | 2022.02.01 |
| [Spring] REQUIRES_NEW과 Exception (REQUIRES_NEW는 정말 독립적인가?) (0) | 2020.10.17 |

